
The field of Natural Language Processing (NLP) has witnessed remarkable advancements with the advent of Large Language Models (LLMs). However, the proliferation of these models comes with challenges such as escalating computational costs, extensive memory requirements, and restricted accessibility. Addressing these concerns, a groundbreaking approach, introduced in the paper [1], proposes 1-bit Transformers, presenting a revolutionary solution to the challenges posed by LLMs.
Update on:
The Problem: Scaling Challenges of LLMs
Large Language Models, particularly those based on Transformer architectures, have become pivotal in various NLP applications. However, their scalability poses formidable challenges. The computational cost for training and inference is substantial, demanding significant resources. Additionally, the immense memory footprint required to store the high-precision weights of these models limits their accessibility, hindering adoption by a broader user base.
The Solution: 1-bit Transformers and BitNet
1. Introducing 1-bit Transformers
The essence of the BitNet proposal lies in 1-bit Transformers, where conventional high-precision weights are replaced with binary values (+1 or -1). This innovation offers several advantages:
- Reduced Memory Footprint: The use of 1-bit weights significantly decreases the memory requirements, addressing one of the major bottlenecks of LLMs.
- Faster Training and Inference: Simpler operations with binary weights lead to lower computational costs, accelerating both the training and inference processes.
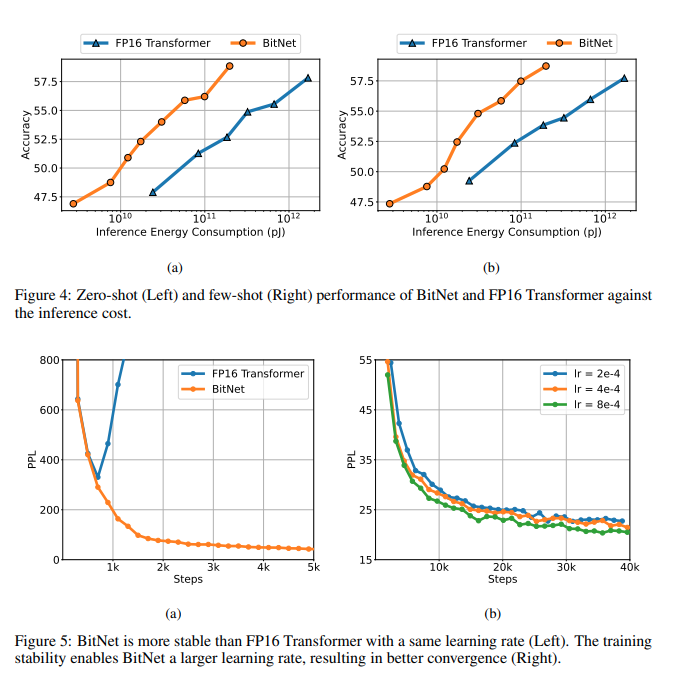
2. Exploring BitNet
BitNet, as detailed in [1], introduces novel architectural components to enhance the capabilities of 1-bit Transformers:
- Training with Quantization Noise Injection: This technique introduces controlled noise during training, mitigating potential accuracy loss associated with the binary representation.
- Adaptive Soft Rounding for Inference: BitNet employs adaptive soft rounding during inference, striking a balance between precision and computational efficiency.
- Benefits of BitNet: BitNet achieves comparable performance to high-precision models across various NLP tasks while offering substantial improvements in memory footprint and computational efficiency.
Introducing BitNet b1.58: Pushing the Boundaries of Efficient Large Language Models
- Innovative Approach: In our continuous pursuit of smaller, faster, and more user-friendly Large Language Models (LLMs), BitNet b1.58 leverages innovative techniques, such as the introduction of a 1.58-bit weight representation.
- Beyond Binary: Departing from its binary predecessor, BitNet b1.58 [2] introduces a unique 1.58-bit weight representation. It goes beyond the traditional positive and negative values by including an additional neutral state (0).
- Balancing Efficiency and Performance: BitNet b1.58 aims to strike a delicate balance between efficiency and performance. By introducing the middle ground of a neutral state, it seeks to retain significant memory and computational cost reductions while potentially overcoming accuracy challenges associated with strictly binary approaches.
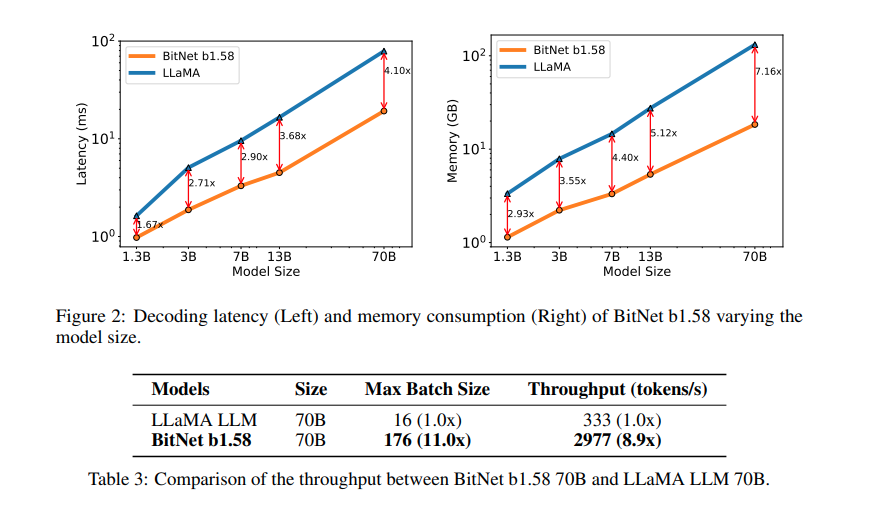
- Nuanced Representation: The groundbreaking aspect lies in the nuanced representation provided by the addition of a neutral state. This allows BitNet b1.58 to capture more intricate nuances in the underlying data, potentially leading to improved model accuracy.
- Ambitious Goal: The overarching ambition behind BitNet b1.58 is clear—to harness the efficiency gains of low-precision models while pushing the boundaries to achieve enhanced accuracy.
- Promise of Accessibility: This advancement represents a promising stride towards realizing the full potential of Large Language Models without compromising on accessibility or imposing insurmountable resource requirements.
- Continuous Evolution: As we explore the possibilities unlocked by BitNet b1.58, we witness a continuous evolution in the development of efficient and powerful language processing models.
Beyond BitNet: Exploring the Future of Efficient LLMs
As we delve into the future of efficient LLMs, the insights from BitNet pave the way for further exploration:
- Advancements in Training Techniques and Hardware Optimization: Research avenues may focus on refining training techniques and optimizing hardware specifically tailored for 1-bit Transformers.
- Extension of BitNet to Different Architectures and Tasks: The potential of extending BitNet’s principles to different LLM architectures and tasks could unlock new possibilities for efficient language processing.
In conclusion, the 1-bit revolution instigated by BitNet and furthered by BitNet b1.58 marks a significant stride towards smaller, faster, and more accessible LLMs.
References
[1] BitNet: Scaling 1-bit Transformers for Large Language Models – https://arxiv.org/pdf/2310.11453.pdf
[2] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits – https://arxiv.org/pdf/2402.17764.pdf